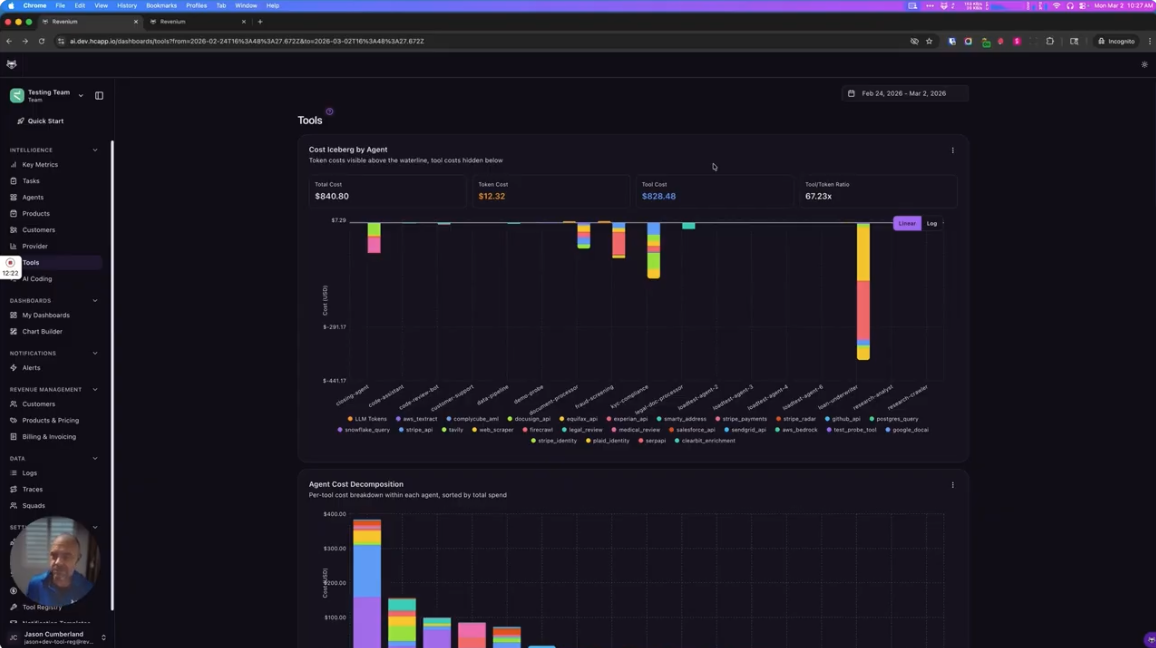
Most LLM observability tools tell you total token spend by model or API key. Very few tell you which customer triggered it, which product it served, and which agent ran it, at the individual transaction level, in production.
Revenium's runtime SDKs instrument every AI transaction asynchronously and capture full attribution: customer, product, feature, and agent, on every call. This gives you a per-transaction breakdown across agents, products, customers, and providers, not estimates or aggregates. Early customers in financial services and SaaS have used this to identify cost centers they had no visibility into before.
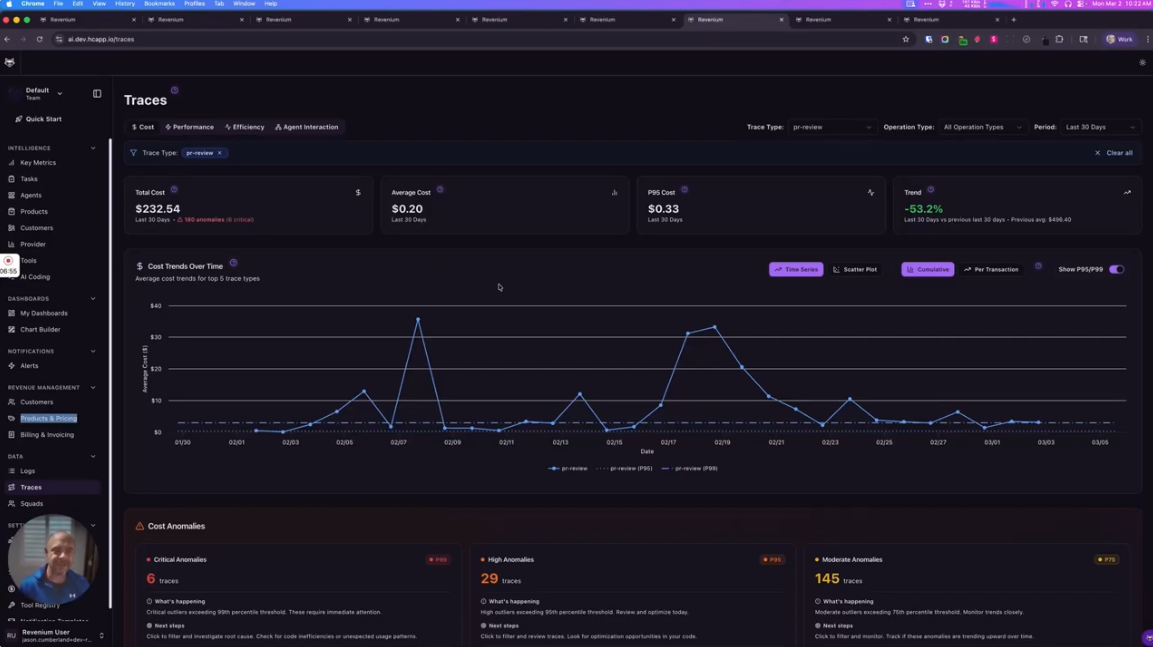
The traces tab introduced at the end of this video is where attribution becomes action: the starting point for identifying exactly which transactions to investigate and fix.